Beyond Show of Hands: Engaging Viewers via Expressive and Scalable Visual Communication in Live Streaming
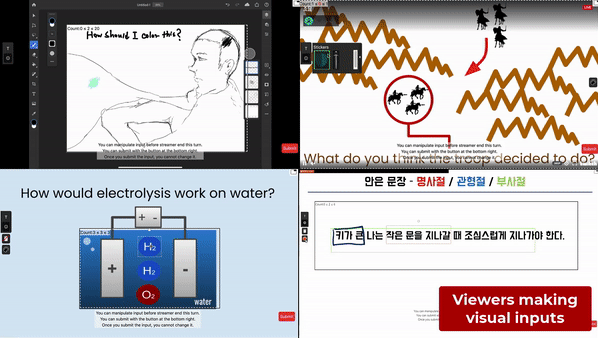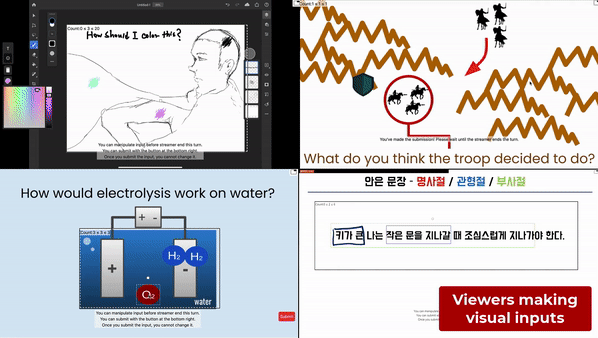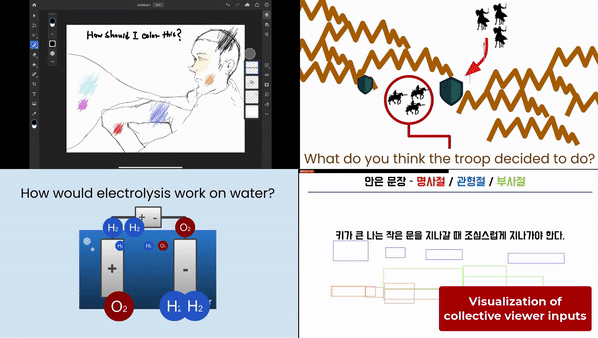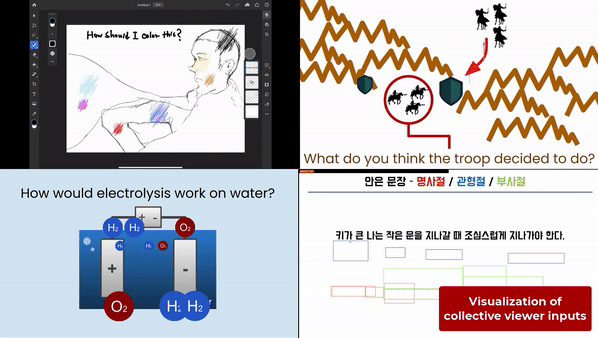
This post summarizes a research paper that introduces a framework and a system that enables scalable viewer visual communication in live streaming. This work is appearing at CHI2021.
Beyond Show of Hands: Engaging Viewers via Expressive and Scalable Visual Communication in Live Streaming, John Joon Young Chung, Hijung Valentina Shin, Haijun Xia, Li-yi Wei, Rubaiat Habib Kazi, In Proceedings of the ACM/SIGCHI Conference on Human Factors in Computing Systems - CHI2021.
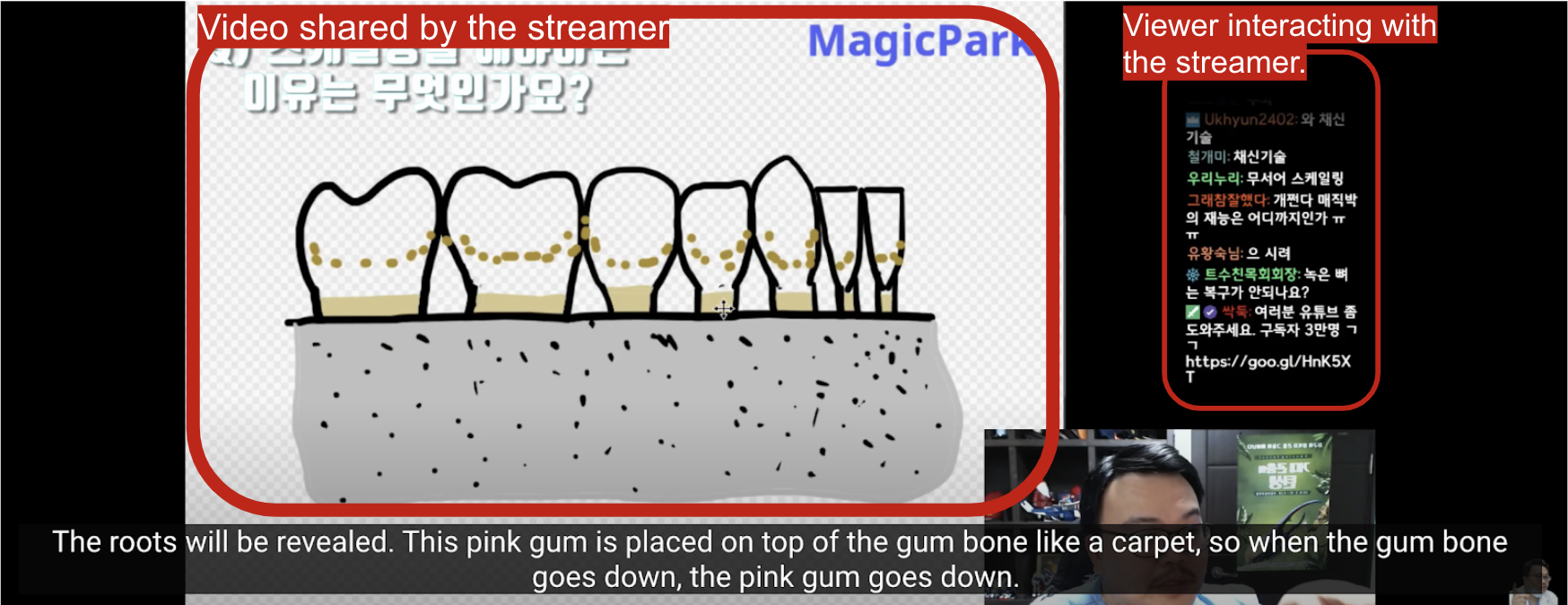 Screenshot from streamer MagicPark
Screenshot from streamer MagicPark
Live streaming is an online streaming media, where the streamer and viewers can communicate in real-time. Streamers can share videos from cameras or the screen of their computer, while viewers can react to the streaming content and participate. This viewer engagement has been considered an integral and enriching element of live streaming.
While viewer participation has been mainly done with chat, some existing platforms and tools tried to allow visual inputs for viewers, as the live streaming videos are visual in itself. Potentially, visual inputs would allow more expressions and enable interaction like visual referencing.

However, one challenge is that visual inputs can be messy and overwhelming if many viewers contribute inputs together. Existing tools ease this overwhelm by only allowing simple visual inputs or narrow use cases, hence losing expressiveness and flexibility. With this challenge, our question was how to enable flexible and scalable viewer visual communication in live streaming.
Design goals
To answer this question, we first interviewed streamers to investigate the requirements of viewer visual communication systems. Accordingly, we identified four design goals:
- G1. Expressiveness: Allow viewers to express themselves flexibly through visual inputs
- G2. Coherency: Collect relevant viewer inputs and present many viewer inputs in an easily understandable way.
- G3. Low Interaction Threshold: Keep interaction easy so that viewers without much skill in creating visual inputs can engage.
- G4. Adaptability: Allow streamers to adapt viewer interactions to the different content and changing context of live streaming.
Visual Input Management Framework
Based on these design goals, we introduce a design framework for building viewer visual communication systems, VIMF (visual input management framework).

VIMF considers viewer visual inputs as a combination of visual attributes, which are visual aspects that convey information, such as shape, size, color, rotation, and position.
For example, in physics live streaming, if a streamer asks viewers to annotate net force applied on a box on the slope, it can take the shape of an arrow, length that accords with the magnitude of the force, and rotation of the direction of the force.
With these visual attributes, VIMF allows streamers to specify, aggregate, and visualize viewer visual inputs according to visual attributes, so that they can manage and sensemake on scalable viewer visual inputs.
Specify
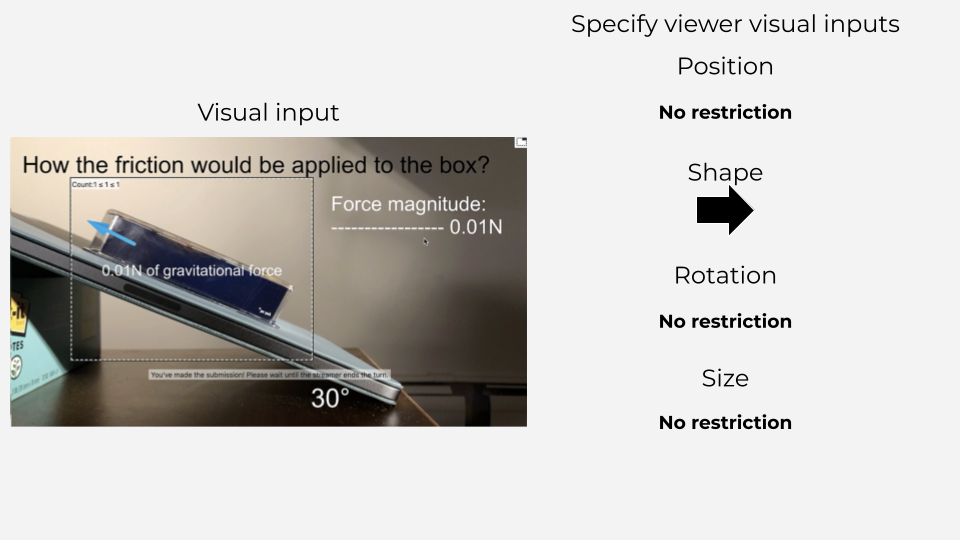
First, VIMF allows streamers to specify visual inputs. Streamers can decide which visual attributes will be allowed for viewers to control. For example, in the above example of physics live streaming, the streamer can only allow viewers to make arrow-shaped inputs. At the same time, the streamer can allow full freedom in the length, position, and direction of the arrow. With this, streamers can specify a necessary level of expressiveness for viewer inputs. Accordingly, the streamer would receive a more coherent set of inputs. At the same time, streamers can allow easy visual inputs if viewers do not have enough knowledge or skills to answer with highly expressive visual inputs.
Aggregate

Second, VIMF allows streamers to aggregate visual inputs. Streamers can run aggregation with visual attributes that the streamers think as important. For example, in the above example, the streamer can aggregate viewer inputs with the size (length) and the rotation (direction) of arrows. As the result of the aggregation, a VIMF-based system outputs several clusters with different sizes and rotations.
Visualize
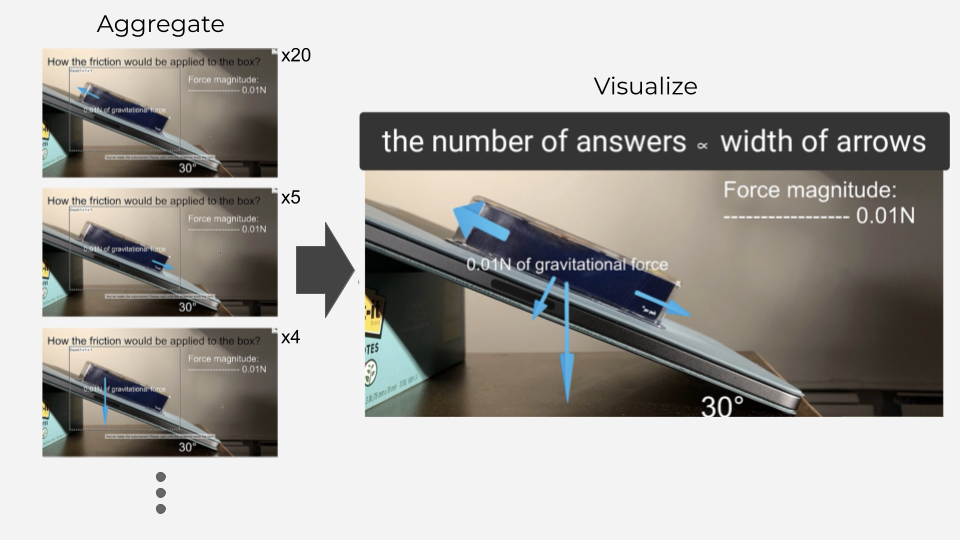
Third, VIMF allows streamers to visualize viewer visual inputs. Streamers can show aggregated results in an easy-to-understand visualization that embeds upon the streaming video. For example, in the above example, the streamer can show each aggregated cluster into each arrow, with the width of arrows indicating the number of people who answered so.
VisPoll
With VIMF, we designed an initial system for expressive and scalable viewer visual communication, VisPoll. VisPoll focuses on visual attributes on a single, static object, which include position, shape, size, rotation, and color. It is also designed with turn-based interaction, allowing streamers to specify when viewers can submit inputs and when to show collected viewer inputs. It allows streamers to more easily manage viewer inputs. Moreover, VisPoll allows streamers to save and load configurations about visual input specifications, aggregations, and visualization so that they can flexibly use visual communications during the streaming.
Application Scenarios
With VisPoll, we introduce a range of application scenarios.
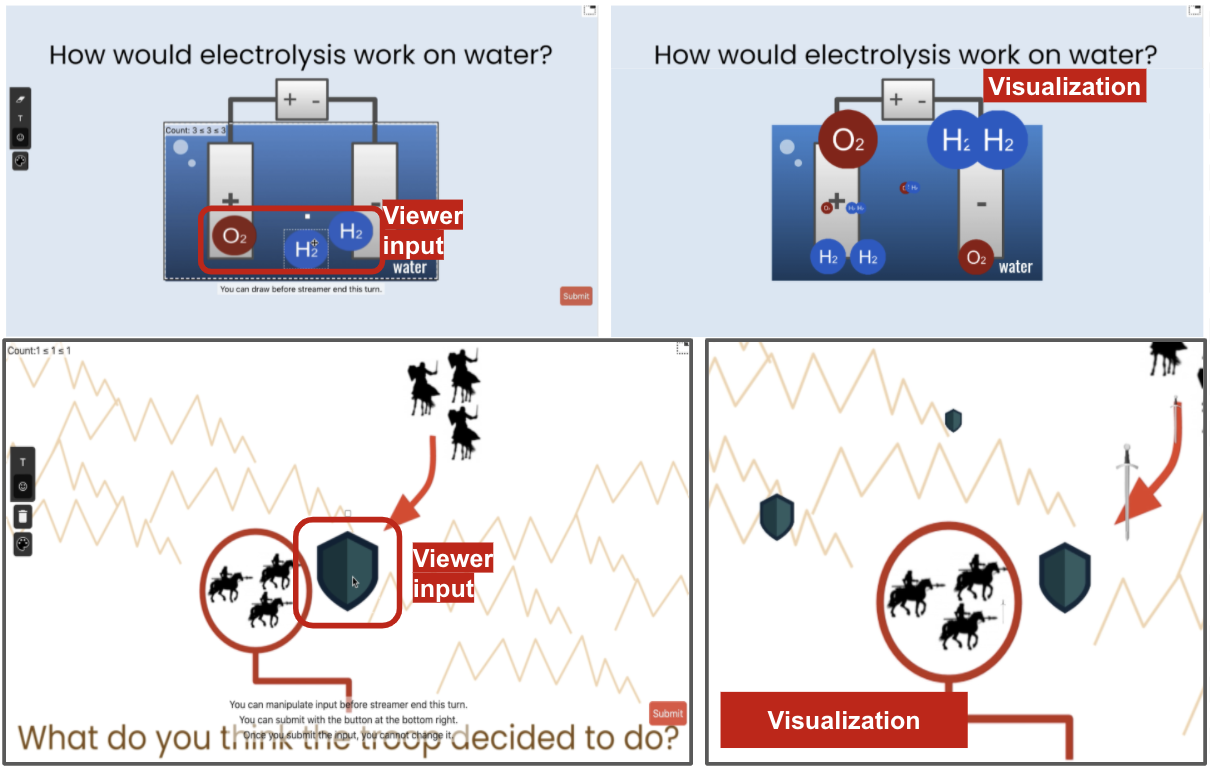
In educational scenarios, streamers can ask questions to student viewers, like “how would electrolysis work on water” in chemistry streaming or “what the troop decided to do” in history streaming. Student viewers would answer these questions with expressive visual inputs, with diagramming-like interactions. Then, the streamer would visualize the aggregated answer, which would help the streamer and viewers to understand how the viewers answered. With this, the streamer would potentially identify misunderstandings within viewers.
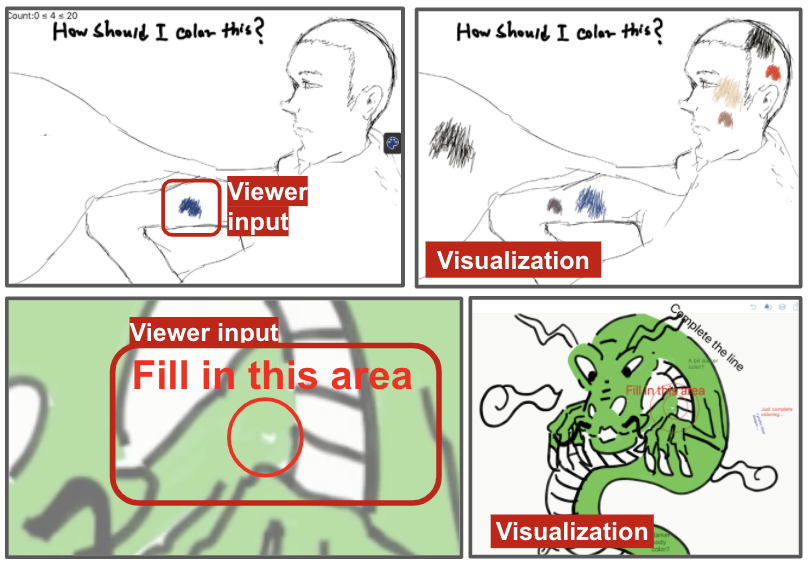
In creative live streaming, VisPoll can be leveraged to get viewer opinions on how to create arts or to collect viewer feedback. By aggregating and visualizing viewer answers, the streamer can understand what the majority’s opinions are, and try to satisfy viewers.
User Study
We also ran user studies with 3 streamers and 43 viewers. Streamers could use VisPoll according to their live streaming contexts.
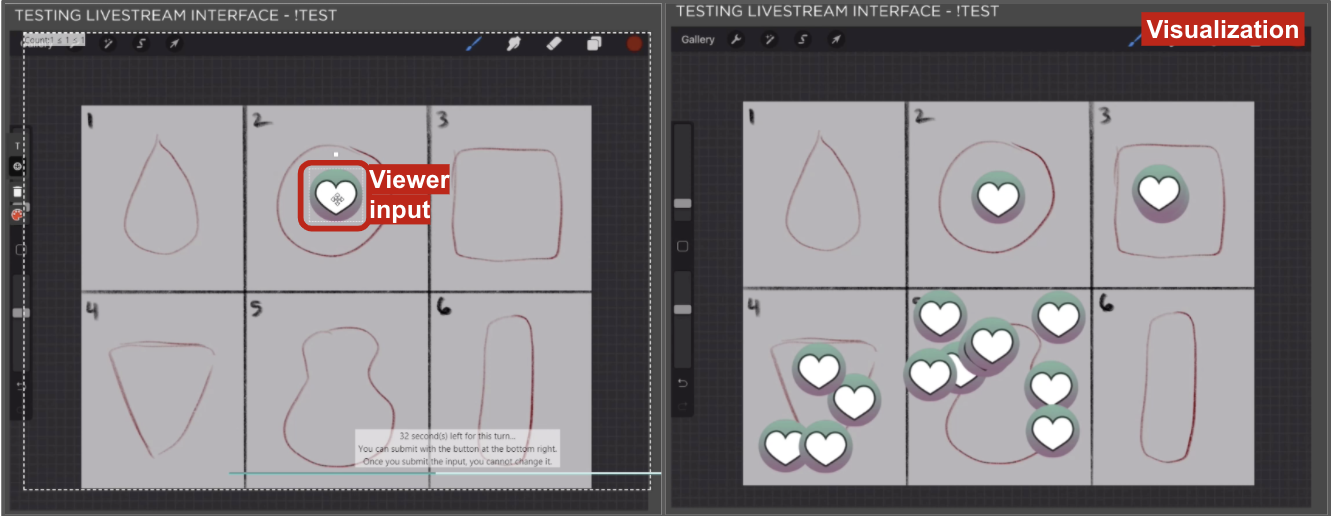
One creative live streamer could collect viewer opinions when deciding what to create. Viewers could place a marker on one of the options, and the streamer could understand what viewers chose by visualizing raw answers on the video.
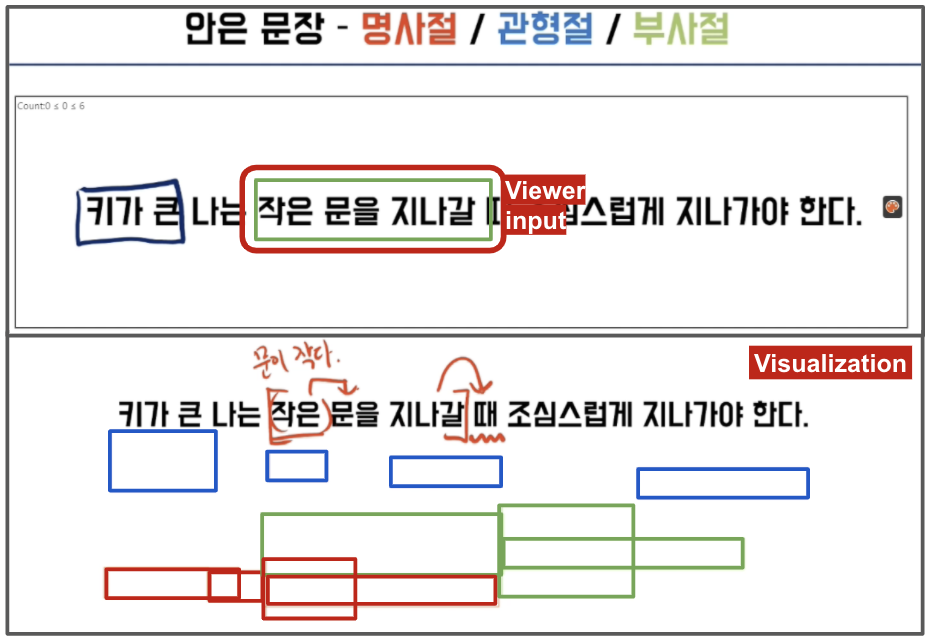
One Korean language arts lecturer could prompt viewers to solve a grammar problem and give adaptive explanations based on how viewers answered. Viewers annotated clauses with boxes, with different colors indicating different roles of clauses. The streamer could visualize viewer inputs with the height of each cluster indicating the number of people who answered so.
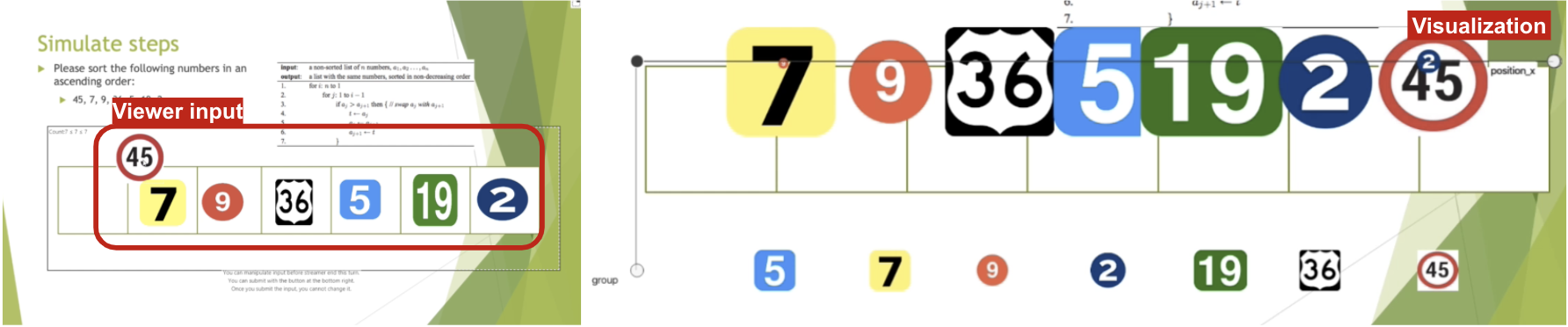
One computer science lecturer asked viewers to solve sorting questions and give explanations based on viewer answers. Viewers could answer with different arrays of elements, and the streamer could visualize different arrays, with size indicating the number of people who answered so.
We found streamers and viewers found VisPoll helpful in understanding the overall inputs from viewers. They also mentioned that they could more engage in the streaming with active participation in the streaming.
To Conclude…
We hope VIMF and VisPoll open up new possibilities in allowing scalable and expressive multi-modal viewer visual interactions. We believe our work can be extended to enable scalable, collective, but sensible construction of visual inputs—such as free drawings or even animations. It would open up more interesting and engaging viewer-streamer interactions in live streamings.